




Habíamos dicho en varias ocasiones anteriores (para que no digan que se es general después de la batalla) que había problemas con las encuestas: Que no era claro que estuviera bien analizado lo de votante probable, las tasas de rechazo (aquí link), que las primarias habían mostrado varias sorpresas (aquí link). Más en general, habíamos enfatizado el hecho que los métodos han de articularse con la realidad social que estudian, su validez depende del estado de esa realidad (link)
Los resultados del 19 de Noviembre mostraron eso con claridad. La Radio de la Universidad de Chile tuvo a bien mostrar un cuadro que es bastante claro.
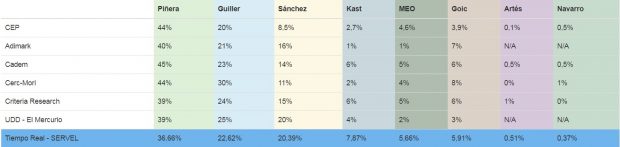
Las principales encuestas tuvieron varios errores importantes para Piñera (10 puntos en varios casos) y Sánchez (12 a 6 puntos), y con una fuerte subestimación de Kast. Más aún, la impresión general -de una votación muy alta de Piñera, de importantes diferencias entre Guillier y Sánchez- resultó claramente errada.
Ahora bien, ¿eso implica que hay un problema de mala fe? ¿Las encuestas de derecha nos engañaron? Y no. CERC que no es de derecha estuvo entre las encuestas con más problemas. UDD-El Mercurio -que la gente que usa esa interpretación diría que es de derecha- estuvo bastante bien.
¿Se equivocaron todas las encuestas? ¿No sirven para nada? Tanto Criteria como UDD obtuvieron estimaciones que resultaron bastante decentes. En general, las encuestas no se equivocaron con Guiller (sólo CERC), y nadie le otorgó muchos votos a Goic (que también era de quien criticaba antes a las encuestas). Adimark, entre las grandes, tuvo los menores errores con Piñera y Sánchez (y dejó de hacer encuestas antes que las otras).
En otras palabras, hay problemas importantes que resolver (¿cómo se calcula votante probable?); pero no todos se equivocaron.
Aquí es importante hacer dos precisiones cruciales. Una de actitud y otra metodológica.
Partamos con la actitud de la reacción. He aquí Mackenna del CEP en Twitter hoy

Para ver otra reacción,Izikson de CADEM a través de la misma red social:

Entre Mackenna e Izkinson está la diferencia entre la seriedad y el burlarse de la población. Entre quien de verdad se cree que las cosas hay que hacerlas bien y quien le da lo mismo. La diferencia entre el mínimo profesionalismo y el vendedor de humo.
Una encuesta es, al final, un instrumento cuantitativo, lo mínimo es que vaya más allá del al orden. La impresión que deja una encuesta no es sólo un tema de orden. Un error de 10 puntos no es un tema de ‘hacer más precisas las estimaciones’.
Al fin y al cabo, basados en resultados electorales y analizar políticamente es posible estimar mejor. En mi oficina se hizo el ejercicio de apuesta en intentar predecir el número de votos de Piñera. Los datos que usamos para ello fueron (a) cuantas personas votaron 1a vuelta el 2013, (b) votación primaria derecha 2017, (c) votación Evelyn Matthei en 2a vuelta el 2013. Basado en ello, el promedio de la oficina fueron 2.6 millones de votos, concentradas las opciones entre 2,3 y 2,5 millones (el nivel mínimo de votación derecha es lo que obtuvo Matthei en 2a vuelta el 2013 y de ahí puede sacar más porque es candidato más fuerte). Los outliers pensaron en 3 millones porque siguieron más bien a las encuestas. Esto es importante porque el mismo Izkinson ha retrucado al hecho de sólo dieron al orden con que ese orden sólo parece obvio dadas las encuestas. Sin ellas también es posible obtener estimaciones.
Luego, una buena encuesta necesita entregar algo más que un buen resultado al bulto. En particular, una buena encuesta electoral.
El segundo tema es metodológico. Es sabido que la encuesta CADEM no cumple con ningún requisito metodológico mínimo. Usar encuestas en punto de afluencia para una encuesta política es impresentable (y de nuevo, eso es sabido y ya había sido dicho en este blog ya el 2015). Y sin embargo, se usaban -no sólo los medios, incluso Kenneth Bunker -que desarrolla en TresQuintos predicciones bayesianas- los usaba. Izkinson realizó varias defensas de su método. Esto es incluso peor porque otras encuestas (Criteria por ejemplo, que recordamos ahora porque sus resultados fueron relativamente decentes) fueron vapuleadas por usar un Panel Online -el mismo Bunker en Twitter las declaró impresentables. Lo que aparecía como mostrando su clara inutilidad era la alta votación de Bea Sánchez. Es bien inconsistente declarar inusable una metodología problemática mientras al mismo tiempo aceptar otra.
Recordemos que los paneles online tienen problemas -el sesgo no se soluciona automáticamente a través de ponderadores. Sin embargo, han sido usados en otros contextos (y en algunos estudios de forma bastante exitosa con muestras claramente sesgadas -hay un estudio del 2015 con usuarios de Xbox que entrega buenos resultados para la encuesta norteamericana, link aquí). Incluso en el caso chileno, aparte de Criteria otras encuestas usando paneles (privadas) dieron resultados razonables. Sabemos que las metodologías tradicionales tienen problemas (tasas de respuesta por ejemplo), y luego hay que probar nuevas metodologías en el contexto actual. Ahora bien, para hacer esas pruebas resulta necesario hacer las cosas con seriedad y cuidado.
Y bien sabemos que seriedad y cuidado no es lo que caracteriza a la encuesta CADEM. Problemas con encuestas hay, fallos los habrá; pero lo mínimo es reconocerlos para poder solucionarlos. Salir defendiendo lo indefendible muestra que no hay mucho interés de hacer las cosas bien. Si de esta debacle al menos se logra que no sea aceptable hacer cualquier cosa, algo se podrá obtener en limpio.
 .
.